Non mais…tu te prends pour qui ? Le sous-titrage à l’épreuve de l’émotion
Indice
1. Choix d’un terrain d’exploration et premières analyses
2. Analyse du sous-titrage des séquences de colère : du verbal au multisémiotique
Abstract
This paper deals with the description and analysis of translation choices in a corpus of subtitled French and Italian films.
Is it possible to explain subtitling tactics by considering all meaning-making signs composing a film? How can we do it?
By defining anger sequences as a unit of meaning, we discuss some methodological issues for the exploration of a limited micro-context, where verbal and non-verbal resources make sense together. The observation of different subtitling tactics, especially when dialogue oral features express anger, will help to study the influence of non-verbal signs on translator’s choices.
Introduction
Au cours de notre travail de recherche doctorale, parmi les différentes problématiques traductologiques soulevées par le sous-titrage, nous nous sommes consacrés aux liens que les sous-titres entrelacent avec l’ensemble des systèmes sémiotiques composant un film.
La question du rôle joué par les signes audiovisuels dans la pratique traductive revient constamment dans les études du domaine mais elle échappe encore à une analyse approfondie pour au moins deux raisons principales: d’un côté la difficulté de penser la traduction au-delà de sa forme verbale, de l’autre l’absence de modèle d’analyse élaboré dans une perspective traductologique et apte à rendre compte de la complexité sémiotique des productions audiovisuelles.
Ainsi, la plupart des analyses menées sur des films sous-titrés considèrent les sous-titres comme des unités verbales en elles-mêmes, détachées du contexte sémiotique dans lequel elles s’insèrent et strictement liées au dialogue de la version originale (Cf. ASSIS ROSA, 2001; TOMASZKIEWICZ, 2001 ; VANDERSCHELDEN, 2001 ; RAMIERE, 2004 ; HOWELL, 2006 ; GUILLOT, 2007). Les choix traductifs sont ainsi décrits et analysés à partir d’approches exclusivement linguistiques, que ce soit dans le cadre de l’approche conversationnelle (comment le sous-titrage modifie la structuration de la conversation) ou dans le cadre de l’approche sociolinguistique (comment le sous-titrage peut rendre compte de certaines variations). C’est ainsi que la question de l’oralité des sous-titres (oralité dans l’écrit) est devenue centrale dans les études du domaine, lesquelles en parlent souvent en terme de « perte », alors que le sous-titrage ne devrait pas seulement référer aux ressources linguistiques de la version originale mais à un tout qui doit être aussi compris dans la société d’arrivée.
L’incapacité de se détacher d’une vision langagière du sous-titrage réside surtout dans l’absence de modèle décrivant les textes multisémiotiques, modèle qui soit efficace et qui permette de comparer aisément différentes traductions. En effet, en adoptant une approche linguistique, on peut choisir d’analyser la restitution d’un segment verbal faisant sens dans un ou plusieurs films, sans avoir aucune difficulté à le repérer dans les dialogues originaux et dans plusieurs films. Par contre, il est bien ardu de choisir une combinatoire précise de signes verbaux et audiovisuels et de les identifier dans un corpus de longs-métrages pour en analyser la traduction, en vertu notamment des possibilités infinies de combinatoires entre les différents systèmes de signes et de la difficulté de séparer un ensemble multisémiotique qui se caractérise par un certain dynamisme et passe à travers des canaux de communication différents.
Le but de notre recherche a été justement de nous interroger sur ces questions, à savoir : comment circonscrire un ensemble verbal et audiovisuel qui soit comparable? comment le décrire ? et comment expliquer les choix traductifs en sous-titrage? Cette contribution présente une partie de nos réflexions et quelques résultats obtenus grâce au choix de séquences de colère comme terrain d’exploration des rapports entre traduction, langues, cultures et non verbal.
Dans un premier temps, nous allons exposer notre démarche d’investigation dans ses enjeux théoriques et pratiques pour arriver aux analyses préliminaires des séquences de colère. Dans un deuxième temps, ce sera le tour des analyses consacrées aux choix traductifs et à l’influence des signes audiovisuels, en particulier des techniques cinématographiques, sur ces choix.
1. Choix d’un terrain d’exploration et premières analyses
1.1 La colère comme point de départ
La premier défi de notre recherche a été celui de définir une unité de sens qui ne se limite pas aux ressources verbales, mais qui soit analysable dans toutes ses composantes verbales et non-verbales et qui puisse être commune à un certain nombre de films. Nous avons donc pensé à une unité narrative comme la séquence ; en outre, nous avons trouvé que la représentation cinématographique de la colère pouvait bien satisfaire les finalités de notre étude.
Le parcours a donc été construit autour des séquences colère. Nous avons avancé par étapes en dégageant le sens de cette émotion à partir de plusieurs perspectives, dans le but de pouvoir nous interroger sur sa traduction avec une connaissance plus ou moins solide de ses significations, de ses fonctions et de ses traits distinctifs. Nous en avons déployé toute la complexité en exploitant différentes disciplines, notamment la psychologie cognitive, la sémantique cognitive et la linguistique.
Les recherches de psychologie cognitive dans le domaine des émotions (EKMAN, 1971, 1994 ; KUPPENS et AL., 2003, 2007) nous ont permis de définir la colère en tant qu’émotion et d’en délimiter la manifestation dans un corpus de douze films - six français et six italiens. Suite à son identification, nous avons pu commencer notre exploration de la construction du sens dans les productions audiovisuelles. Pour ce faire, nous sommes partis à la fois de la dimension narrative qui détermine la fonction de la colère et du dialogue dans la séquence (VANOYE, 1998) pour arriver à la dimension linguistique (recherches sur la prosodie des émotions, études des énoncés blessants, de la politesse et des actes de langage), en passant par les modèles sémantico-cognitifs (concept de script) qui peuvent être à la base de la représentation cinématographique de cette émotion.
L’épisode de la colère s’est révélé une véritable unité narrative cohérente et récurrente dans les films, présentant des caractéristiques spécifiques en fonction des sujets traités et de sa distribution au cours de la narration. Suivant notre orientation traductologique, nous l’avons ainsi définie en tant qu’unité de sens, les fonctions dramatiques du dialogue étant déterminées par l’emplacement de la séquence de colère dans la narration.
1.2 Les invariants verbaux du script de la colère : la parole émotionnelle
Le niveau sémantique de la séquence une fois circonscrit, nous avons proposé le concept de script (MINSKY, 1975 ; SCHANK et ABELSON, 1977) pour nous approcher de l’analyse de la structure de l’unité de sens. À travers la notion de script, nous avons cerné la structure générale des séquences de colère et nous en avons analysé le composant verbal.
Tout comme dans un script, les ressources verbales employées au cours des différentes scènes1
suivent un modèle : les personnages procèdent par attaques, contre-attaques, avec des réactions actives ou passives par rapport à la colère.
Pour les attaques et les contre-attaques, l’intention de blesser et de dévaloriser la face de l’autre se manifeste en gros de la même façon (Cf. GOFFMAN, 1993):
- soit dans l’emploi d’expressions et termes grossiers ou insultes (Cf. LAGORGETTE et LARRIVEE, 2004), comme c’est le cas dans ces deux extraits :
KEVIN: Non mais… tu te prends pour qui ? T'es qu'une vraie petite conne, voilà ! T'es une sale petite conne!(Embrassez qui vous voudrez, M. Blanc, 2002)2
MIMMO:Oh ma… ma t'abbiamo aspettato due ore in quel cazzo d'autogrill! (Pane e tulipani, S. Soldini, 2000)
- soit dans l’acte de langage (reproche, refus, mépris, provocation, menace) transmis par l’ensemble d’une répartie isolée ou en relation avec le cotexte, dont les reparties menaçantes ci-dessous sont un exemple (Cf. LAGORGETTE, 2006):
VERONIQUE:Jérôme, tu sais quoi en ce moment ? Si j'avais une arme, je te descendrais ! (Embrassez qui vous voudrez, M. Blanc, 2002)
LIVIA:Adriano! Se esci da quella porta! M'incazzo come 'na bestia, ha' capito? (L’ultimo bacio, G. Muccino,2001)
Pour ce qui est de l’effet de la colère sur la construction de l’expression verbale, nous l’avons dégagé surtout dans l’emploi des répétitions, mais aussi dans les interjections qui ont tendance à augmenter là où le personnage paraît ne plus avoir le contrôle sur ses énoncés.
La charge émotionnelle peut résulter en outre du déploiement de ressources verbales tout au long de la séquence. Le crescendo peut en effet se construire soit en autonomie par des monologues d’attaques, sans que le cotexte appartenant à d’autres personnages que le locuteur en colère ne l’alimente; soit en interaction, c’est-à-dire par rapport au cotexte appartenant à d’autres personnages que le locuteur en colère ; soit en alternant interaction et monologue. Voici deux exemples de monologues d’attaques, où finalement les deux personnages se défoulent sans que l’autre ne puisse intervenir (dans le deuxième extrait le personnage victime de l’attaque apparaît à l’écran d’un téléviseur):
JEROME: Écoute Véronique, t'as pas l'air de vouloir comprendre, alors je vais t' mett' une dernière fois les points sur les "i" : on n'a plus d' pognon, plus rien, on est à sec ; la Volvo elle est pas en révision, j'ai dû la vend' pour payer l'essence du voyage et la location d'la caravane ; alors ou tu t'y fais ou on rent', c'est ça ou rien ! J'ai été assez clair ? (Embrassez qui vous voudrez, M. Blanc, 2002)
NANNI: Non ti far mettere in mezzo sulla giustizia proprio da Berlusconi! D'Alema di' una cosa di sinistra! Di' una cosa anche non di sinistra, di civiltà! D'Alema di' una cosa! Di' qualcosa, reagisci! (Aprile, N. Moretti, 1998)
La comparaison entre les dialogues de nos séquences a montré que l’ensemble de ces traits sont communs aux deux communautés linguistiques française et italienne, ce qui nous a amené à définir ces caractéristiques comme spécifiques de la parole émotionnelle (CF. FRANZELLI, 2008b).
Cependant au niveau des variations linguistiques, véhiculant pour nous l’état émotionnel des personnages, nos séquences présentent des différences entre français et italien.
Le français dispose de fait de traits morphosyntaxiques et lexicaux au caractère synthétique pouvant refléter l’état émotionnel des personnages qui ne relèvent pas d’une variation diatopique, comme par exemple l’élision de « ne » dans la négation, l’emploi de « ça » au lieu de « cela », de termes argotiques (ex. « pognon », « truc », « gosse », «fricoter », «nichons », «gonzesse ») et de troncations («alors je vais t' mett' une dernière fois les points sur les "i" ») .
L’italien, par contre, si on exclut des expressions et des termes grossiers, peut s’appuyer surtout sur la variation diatopique pour marquer un écart de la langue standard au niveau morphosyntaxique et lexical, comme c’est le cas dans ces extraits de dialogues tirés de Romanzo Criminale (M. Placido, 2005)
LIBANO: Ho deciso che 'n te pago.
LIBANO: L'infami come lui me fanno schifo me fan‘!
LIBANO: T'ho ammazzato 'r padrone non hai detto “A”.
La direction du transfert est donc un facteur important à considérer pour l’explication de certaines tactiques de sous-titrage, mais il faut aussi tenir compte d’autres signes porteurs de sens dans la séquence et pouvant relativiser cette contrainte purement linguistique. Ainsi nous avons constaté que toute expression verbale peut devenir une attaque; cela dépend du contexte dans lequel elle prend place, de la volonté de celui qui attaque en premier, et des réactions des autres personnages, aussi bien que des éléments sonores et posturo-mimo-gestuels qui se manifestent (Cf. LAGORGETTE, 2006). La parole émotionnelle est donc bien définissable surtout par rapport à cet ensemble de facteurs.
1.3 Le modèle descriptif
Dans la construction d’un modèle descriptif (Figures 1 et 2) apte à restituer les liens entre le verbal et les signes audiovisuels, nous avons ainsi essayé de mettre à plat tous les signes pouvant donner des informations au cours de la séquence. L’approche multimodale (TAYLOR, 2003 ; BALDRY et THIBAULT, 2006) a inspiré la construction de notre modèle descriptif à travers lequel nous avons essayé de donner la même importance à tous les signes.
En considérant que les dialogues des films sont créés pour un public et agissent donc au « niveau vertical »3
de la communication (c’est-à-dire entre le film et les récepteurs) plutôt qu’au « niveau horizontal » (entre les personnages), il nous a semblé pertinent d’opérer une distinction entre les signes dialogiques (SD), propres à une conversation ordinaire et les signes filmiques (SF), propres à toute production audiovisuelle et déterminant la perception des signes dialogiques par le spectateur.Dans le premier groupe, nous avons inclus tous les signes qui concernent potentiellement les personnages parlant dans la séquence: leur expressionverbale (SD verbaux), leur expression vocale (SD sonores), et leur expression visuelle (SD visuels) à travers la mimique faciale et les gestes. Concernant les signes dialogiques sonores (SD sonores), nous avons élargi notre description à la prosodie des reparties, laquelle a été négligée par l’approche multimodale, mais qui nous a paru importante dans l’analyse de nos séquences en raison du rôle joué par la fréquence fondamentale, l’intensité et le débit dans la définition des universaux caractérisant les émotions de base. La colère serait en effet marquée par une fréquence fondamentale (fo) et une intensité (Int.) hautes ainsi que par un débit (D) rapide ; contrairement à la tristesse, par exemple, laquelle serait déterminée par des valeurs basses de fo et d’ Int, et par un D lent (Cf. POGGI et MAGNO CALDOGNETTO, 2004).
Dans le deuxième groupe, nous avons rassemblé tout ce qui n’est pas lié à la performance des locuteurs, y compris les techniques cinématographiques et les effets sonores, tels que les bruits et la musique.4
Cette distinction nous a permis à la fois de considérerla performance des personnages parlant (in ou hors champ), censéesignifier leur état émotionnel de la même manière dans toutes les séquences, et deconsidérer sa modification en fonction des signes filmiques employés. Cela afin de repérer des combinatoires de signesrécurrentes et d’opérer des comparaisons.
Le modèle descriptif ainsi structuré a cependant montré que chaque système de signes suitson rythme, même à l’intérieur des signes dialogiques, et que toute description subitcette différenciation : une même répartie peut s’étaler sur plusieurschangements de plan et de perspective, combinant par exemple des chevauchements deparoles, une musique qui a commencé à être jouée bien avant, des images sombress’alternant à d’autres plus claires…Par conséquent il est impossible de repérer unsegment minimal commun, même là où les signes dialogiques visuels et sonores peuventêtre en harmonie avec l’expression verbale (dans notre cas véhiculant de la colère). Il faut signaler en outre qu’au niveau des signes dialogiques sonores, notre description prosodique ne montre pas de valeurs signalant clairement l’état émotionnel des personnages, ce qui donne une certaine importance aux ressources verbales et visuelles pour désambiguïser l’interprétation des réparties.
Compte tenu des spécificités de la pratique du sous-titrage, considéré comme une « traduction sélective » (GAMBIER, 2006: 33), nous allons maintenant présenter quelques observations concernant la traduction de la parole émotionnelle.5
L’exploitation du modèle descriptif permettra par la suite de se pencher sur le contexte sémiotique qui l’accompagne et de réfléchir notamment sur l’influence des techniques cinématographiques.
2. Analyse du sous-titrage des séquences de colère : du verbal au multisémiotique
2.1 La traduction de la parole émotionnelle
Nous avons procédé à l’analyse des choix traductifs en nous penchant sur le sous-titrage de la parole émotionnelle.
Le passage de l’oral à l’écrit dans des conditions contraignantes paraît expliquer un certain nombre de réductions sous forme d’omission ou de compression. Cependant ces changements n’impliquent pas la perte du sens du dialogue des séquences. En effet, les sous-titres se caractérisent par une augmentation du sémantisme négatif des réparties, dû non seulement à la réduction de la plupart des traits relevant de la tension émotionnelle, mais aussi à l’emploi de tactiques d’explicitation et de
simplification des actes de la colère. Ces modifications par rapport au dialogue original plient davantage la langue à la fonction du dialogue original dans la narration, afin de rendre compréhensible pour un public l’état émotionnel des personnages. Cet effet positif nous paraît spécifique des séquences de colère, car dans d’autres situations ces mêmes changements peuvent altérer la perception de l’interaction, les échanges devenant en effet plus froids.
Cela dit, les réductions concernant les traits marquant de l’expressivité ne sont pas systématiques, notamment dans les sous-titres français qui emploient les ressources spécifiques de la langue d’arrivée pour rendre l’état émotionnel des personnages, parfois même sans que cela soit demandé par les réparties originales. Cela paraît évident dans les exemples qui suivent où l’on trouve l’emploi d’expressions argotiques remplaçant le registre standard de la version originale:
- «je me fais tabasser » rend « mi faccio dare un sacco di botte »;
- « flics » correspond à « polizia » ;
- « on va encore se taper une nuit blanche » équivaut à « non ci fa dormire neanche stanotte»;
- « se tirer » est employé pour « andarsene »;
Dans le passage de l’italien au français, on repère également la substitution d’une variation diastratique par une variation diatopique:
- « Je te cause pas. Casse-toi. » pour « Ma che sto à parlà co’ te? »;
- « fissa » pour « ma subbito però»;6
- « bâtons » pour « testoni »; « pognon » ou « fric » pour « i sordi »;
- «Même comme clebs, tu vaux pas un rond.» pour « manco come cane vali ‘na lira»;
- «J’ai tué ton patron / et t’as pas moufté » pour « t’ho ammazzato ‘r padrone non hai detto “A” »
Finalement, l’ensemble des sous-titres français révèle la présence de traits morphosyntaxiques marquant un éloignement du registre standard qui n’ont pas d’équivalent direct en italien.
Par contre, les sous-titres italiens ont tendance à rendre moins expressifs les personnages français, neutralisant non seulement ces traits qui n’ont pas de correspondants directs dans la langue d’arrivée (comme par exemple l’emploi de « ça » ou l’élision de « ne ») mais aussi des expressions argotique ou grossières pouvant pourtant aisément être rendues. C’est le cas dans le sous-titrage de l’extrait précédemment tiré de Embrassez qui vous voudrez (M. Blanc, 2002). Jérôme vient d’être provoqué par sa femme Véronique, laquelle prétend mener une vie de riche alors que son mari n’a plus d’argent ; il réagit par son monologue d’attaque :
|
DIALOGUE
|
SOUS-TITRES
|
|
JEROME: Écoute Véronique, t'as pas l'air de vouloir comprendre, alors je vais t' mett' une dernière fois les points sur les "i" :
|
Véro [sic.], provo a spiegartelo / per l’ultima volta.
|
|
JEROME : on n'a plus d' pognon, plus rien, on est à sec ;
|
Non abbiamo più soldi.
|
|
JEROME: la Volvo elle est pas en révision, j'ai dû la vend' pour payer l'essence du voyage et la location d'la caravane ; alors ou tu t'y fais ou on rent', c'est ça ou rien !
|
Ho venduto la Volvo per pagare / l’affitto della roulotte.
|
|
JEROME: J'ai été assez clair ?
|
Sono stato chiaro ?
|
Il en résulte que dans la traduction en français, les réparties des personnages italiens paraissent parfois plus expressives que dans l’original, alors que dans la traduction en italien, les réparties des personnages français le deviennent moins. Il a été naturel de se poser la question du cliché, comme si par les sous-titres on voulait consciemment ou inconsciemment alimenter les stéréotypes sur les Italiens et les Français, les uns plus passionnels et relâchés, les autres plus polis et contrôlés.
Cependant dans l’étude d’un seul long-métrage, il serait sans doute difficile de distinguer cet effet caricatural, étant donné qu’il ne s’agit pas de choix traductifs systématiques, mais seulement de choix possibles au cours de la narration. En outre, ces remarques sont relatives puisqu’elles se bornent aux ressources verbales, là où d’autres facteurs relevant de l’ensemble multisémiotique pourraient favoriser un choix traductif plutôt qu’un autre. Nous pensons que c’est justement la non-systématicité de ces choix par rapport aux invariants verbaux de la colère qui invite à s’interroger sur le rôle des signes audiovisuels dans le sous-titrage.
2.2 La relation entre les choix traductifs et les techniques cinématographiques
En nous focalisant sur l’emploi des techniques cinématographiques par rapport aux différents choix traductifs, il nous semble que les mouvements de caméra déterminent souvent la complexité des combinatoires de signes audiovisuels et que par conséquent ils aient une certaine incidence sur le sous-titrage. Nous avons repéré deux tendances extrêmement opposées qui vont de la traduction littérale à la substitution des réparties dans les sous-titres en fonction des techniques cinématographiques employées.
La traduction littérale est en effet plus fréquente lorsque le contexte sémiotique est moins complexe car la caméra est fixe sur les personnages parlant qui apparaissent alors en gros plan. La synchronisation avec le rythme du dialogue est de la sorte favorisée. Le cas le plus éclatant est celui de Aprile (Figure 1), où l’emploi d’un plan séquence (toute la séquence est tournée avec un plan serré sur le buste de Nanni) focalise l’attention sur le personnage et sur son état émotionnel.
|
DIALOGUE
|
SOUS-TITRES
|
|
NANNI: Non dobbiamo reagire, eh, nervi saldi,
|
Il ne faut pas réagir./ Du sang-froid.
|
|
NANNI: dobbiamo rassicurare…
|
Nous devons rassurer.
|
|
NANNI : …a forza di rassicurare c'arriva una bastonata il giorno delle elezioni!
|
A force de rassurer,/ On va se prendre une raclée!
|
|
NANNI : Ho voglia di litigare con qualcuno! Ho voglia di litigare con qualcuno ! Ora…
|
J’ai envie / de m’engueuler avec quelqu’un!
|
|
NANNI: ..prendo un automobilista, mi faccio dare un sacco di botte!
|
Je prends un automobiliste / au hasard…et je me fais tabasser.
|
|
NANNI : Ho bisogno di litigare! Ho bisogno di litigare!
|
J’ai besoin de me disputer !
|
La traduction reste également près du personnage et cherche à restituer son état émotionnel, aussi en fonction des signes dialogiques visuels : lorsque Nanni donne des coups de poing à la fenêtre de sa voiture, son registre devient plus familier que dans la version originale. Ainsi « litigare » est rendu par « engueuler » et non pas par « se disputer » qui est employé par la suite.
Par contre, quand le contexte sémiotique devient complexe (Figure 2), à cause des mouvements de caméra fréquents, auxquels s’ajoutent souvent des bruits et de la musique au rythme serré, la traduction s’éloigne des dialogues originaux et cherche la cohérence entre la situation d’énonciation et les sous-titres. A travers des tactiques d’omission et de substitution, la synchronisation avec le rythme du dialogue peut donc être délaissée en faveur de la synchronie avec les signes visuels ou bien de la cohérence avec le contexte communicationnel. Par conséquent un sous-titre peut être l’ensemble de trois réparties prononcées hors-champ par deux personnages différents, alors qu’un plan serré sur un troisième personnage invite le spectateur à en observer l’attitude, à s’identifier avec lui et à faire des prévisions sur ce qui va suivre, et qu’une musique hors-champ se mélange aux voix des personnages. Ces éléments pris ensemble peuvent donner un sous-titre constitué d’un seul énoncé qui n’appartient plus à un locuteur précis et qui s’éloigne des réparties originales, mais garde simplement l’effet de contemporanéité des événements permettant au spectateur de faire le lien entre l’image et ce qu’il lit. C’est le cas, par exemple dans la traduction d’une séquence violente tirée de Romanzo criminale (Annexes, Figure 2) où Dandy, amoureux de Patrizia, se bat avec un inconnu pour que ce dernier ne danse plus avec elle. La caméra se déplace cependant sur un autre personnage qui observe la scène, on entend de la sorte seulement les voix de Dandy et de l’inconnu sans les voir :
|
DIALOGUE
|
SOUS-TITRES
|
|
INCONNU: Va a fa du passi che è meyo!
DANDY: Ma fattie te du passi ! INCONNU: Levate… |
Va voir ailleurs.
|
Les signes audiovisuels jouent de la sorte un rôle important dans le choix des tactiques de sous-titrage, ne serait-ce que parce que leurs combinatoires obligent le sous-titreur à se donner des priorités. Ce dernier crée les sous-titres en considérant tantôt seulement les ressources verbales et le rythme des productions, tantôt les réparties et un geste, tantôt un mot et sa prononciation, tantôt plusieurs réparties et un changement de plan. Cela en fonction de sa propre perception du film et de ce qu’il pense être l’intérêt du spectateur ciblé.
Compte tenu de ces considérations, nous pouvons affirmer les tactiques de traduction peuvent s’appuyer tout autant sur le dialogue original que sur le contexte sémiotique constituant la séquence jusqu’à créer de nouveaux rapports entre les ressources verbales et les signes audiovisuels. La vision stéréotypée des cultures de départ paraît ainsi jouer un rôle secondaire dans le sous-titrage des séquences de colère.
Conclusion
Par notre brève contribution nous espérons avoir montré comment la délimitation d’un ensemble multisémiotique devient une tâche paradoxale lorsqu’elle implique la présence de divers systèmes de signes suivant chacun son rythme et ses règles spécifiques.
Si la description de tous les signes constituant l’unité de sens paraît faisable, en procédant, comme dans notre modèle descriptif, par des segmentations et en séparant les différents systèmes sémiotiques, l’analyse de leur influence est par contre bien difficile. Cette difficulté relève principalement du fait que notre description a isolé et rendu statiques des signes qui sont inter-reliés et dynamiques. C’est pourquoi l’analyse ne peut pas s’arrêter sur des segments précis, qui correspondent par exemple à un énoncé ou à un sous-titre, ni considérer séparément les différents signes en rapport avec le verbal, mais doit souvent tenir compte du déploiement sémiotique de la séquence en entier. Il y a tension entre notre approche analytique et la perception globale, synthétisante d’un film.
La modélisation de tous les éléments multisémiotiques relève en effet d’une vision complexe des productions audiovisuelles comme les films, mais notre approche est encore trop statique, car la délimitation de l’unité de traduction n’est faisable qu’en considérant la subjectivité des perceptions, c’est-à-dire ce qui attire l’attention des sous-titreurs lorsqu’ils décident de leurs priorités en fonction du récepteur final.
La question de la réception nous paraît fondamentale, tout d’abord afin de circonscrire ce que le traducteur observe dans les productions audiovisuelles avant de sous-titrer. Nous avons en effet donné une importance équitable à tous les signes constitutifs d’un film, ce qui est une nécessité de l’approche analytique, mais l’approche du sous-titreur est globale. C’est pourquoi l’observation de sa pratique, en adoptant par exemple l’oculométrie, pourrait révéler ce qui se passe face aux ensembles multisémiotiques, comme ceux de nos séquences de colère. Nous pourrions alors hiérarchiser les signes décrits dans notre modèle en fonction de leur importance dans le processus de traduction et mieux définir l’étendue de l’unité de traduction en sous-titrage.
La réception des films sous-titrés par les spectateurs est une autre question à explorer, d’autant plus dans deux pays peu accoutumés au sous-titrage comme la France et l’Italie. Il serait intéressant de comprendre comment les spectateurs italiens et français arrivent à partager leur attention entre les sous-titres et le film et quels liens ils tissent entre eux.
Bigliographie
A. ASSIS ROSA, «Features of oral and written communication in subtitling», in Y. Gambier et H. Gottlieb, H. (sous la dir. de), (Multi)Media Translation. Concepts, Practices and Research, Philadelphia et Amsterdam, John Benjamins, 2001, p. 213-221.
A. BALDRY et P. THIBAULT, Multimodal Transcription and Text Analysis. A multimedia toolkit andcoursebook, London,Equinox, 2006.
P. EKMAN, Emotion in the Human Face, Paris, Editions de la Maison des Sciences de l’Homme, 1971.
P. EKMAN et R.J. DAVIDSON, (sous la dir. de), The nature of emotion. Fundamental Questions, New York, Oxford, Oxford University Press, 1994.
V. FRANZELLI, «Anger sequences as a unit of meaning for the investigation of subtitling strategies and tactics», in P. Boulogne (sous la dir. de), Translation and Its Others. Selected Papers of the CETRA Research Seminar in Translation Studies 2007, 2008a, http://www.kuleuven.be/cetra/papers/papers.html.
V. FRANZELLI, «Traduire la parole émotionnelle en sous-titrage : colère et identités», ELA (Etudes de linguistique appliquée), 2008b, n. 150, p. 221-244.
V. FRANZELLI, « Séquences de colère pour une unité de sens. Aspects verbaux et non-verbaux dans une perspective traductologique de sous-titrage », Cahiers de Recherche de l’École Doctorale en Linguistique française, 2008c, n. 2, p. 107-127.
Y. GAMBIER, «Le sous-titrage : une traduction sélective», in J. Tommola et Y. Gambier, Y. (sous la dir. de), Translating and Interpreting. Training andResearch, Turku, Turun Yliopisto, 2006, p.21-37.
E. GOFFMAN, Les rites d’interaction, Paris, Les Editions de Minuit, 1993.
M.-N.Guillot, « Oral et illusion d’oral : indices d’oralité dans les sous-titres de dialogues de film », Meta, 2007, n. 52, 2, p. 239-259.
P. HOWELL, «Character voice in anime subtitles», Perspectives, 2006, n.14, 4, p.292 -305.
P. KUPPENS et al., «The appraisal basis of anger: Specificity, necessity and sufficiency of components». Emotion, 2003, n. 3, p. 254-269.
P. KUPPENS et al., «Individual differences in patterns of appraisal and anger experience», Cognition & Emotion, 2007, n. 21, p. 689-713.
D. LAGORGETTE et P. LARRIVÉE (sous la dir. de), « Les insultes : approches sémantiques et pragmatiques », Langue Française, 2004, n. 144.
D. LAGORGETTE, « Insultes et conflit : de la provocation à la résolution – et retour ? », in J. Pain, J. et D. Leeman (sous la dir. de), Crises, conflits, médiations, Cahiers des Etudes doctorales de Paris 10, 2006, n. 5, p.26-44.
M. MINSKY, « A Framework for Representing Knowledge », in P. Winston (sous la dir. de), The Psychology of Computer Vision, McGraw-Hill, 1975.
I. POGGI et E. MAGNO CALDOGNETTO, «Il parlato emotivo. Aspetti cognitivi, linguistici e fonetici», in F. Albano Leoni et al. (sous la dir. de), Atti del Convegno «Il parlato italiano», Napoli, 12-15 febbraio 2003, Napoli, D’Auria, 2004.
N. RAMIÈRE, « Comment le sous-titrage et le doublage peuvent modifier la perception d’un film. Analyse contrastive des versions sous-titrée et doublée en français du film d’Elia Kazan, A Streetcar Named Desire (1951) », 2004, Meta, n. 49,1, p. 102-14.
A. REMAEL, «Mainstream Narrative Film Dialogue and Subtitling», The Translator, 2003, n. 9, 2, p.225-245.
J.-P. ROSSI, Psychologie de la mémoire. De la mémoire épisodique à la mémoiresémantique, Bruxelles, De Boeck, 2005.
R.C. SCHANK et R. P. ABELSON, Scripts, plans, goals, and understanding: An inquiry into human knowledge structures, Hillsdale, NJ, Lawrence Erlbaum, 1977.
C. TAYLOR, «Multimodal Transcription in the Analysis, Translation and Subtitling of Italian Films», The translator, 2003, n. 9, 2, p. 191-204.
T. TOMASZKIEWICZ, «La structure des dialogues filmiques : conséquences pour le sous-titrage», in M. Ballard (sous la dir. de), Oralité et traduction, Arras, Artois Presses Université, 2001, p. 381-399.
VANDERSCHELDEN, « Le sous-titrage des classes sociales dans La vie est unlong fleuve tranquille », in M. Ballard (sous la dir. de), Oralité et traduction, Arras, Artois Presses Université, 2001, p. 361-379.
F. VANOYE, La sceneggiatura. Forme, dispositivi, modelli, Torino, Lindau, 1998.
Filmographie
Conte d’été, Eric Rohmer, France,1996.
La vita è bella / La vie est belle, Roberto Benigni, Italie,1997.
Aprile / Aprile, Nanni Moretti, Italie, 1998.
Pane e tulipani / Pains, tulipes et comédie, Silvio Soldini, Italie, 2000.
L’auberge espagnole, Cédric Klapisch, France, 2001.
L’ultimo bacio / Juste un kaiser, Gabriele Muccino, Italie, 2001.
Sur mes lèvres, Jacques Audiard, France, 2001.
Embrassez qui vous voudrez, 2002, Michel Blanc, France.
La meglio gioventù / Nos meilleures années, 2003, Marco-Tullio Giordana, Italie.
Un long dimanche de fiançailles, 2004, Jean-Pierre Jeunet, France.
Caché, 2005, Michael Haneke, France.
Romanzo criminale / Romanzo criminale, 2005, Michele Placido, Italie.
Figures
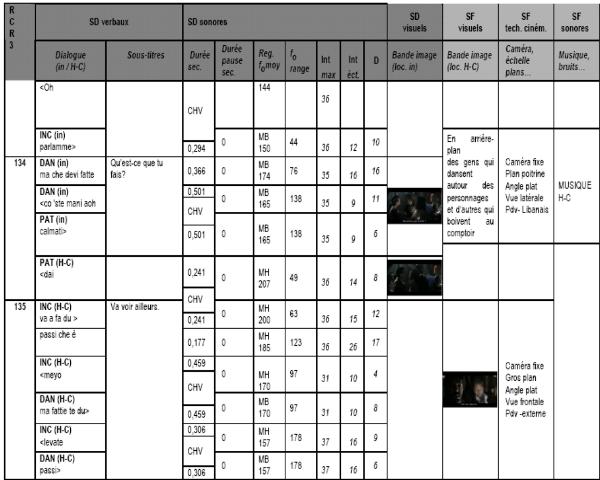
Figure 1 – Aprile (N. Moretti, 1998)
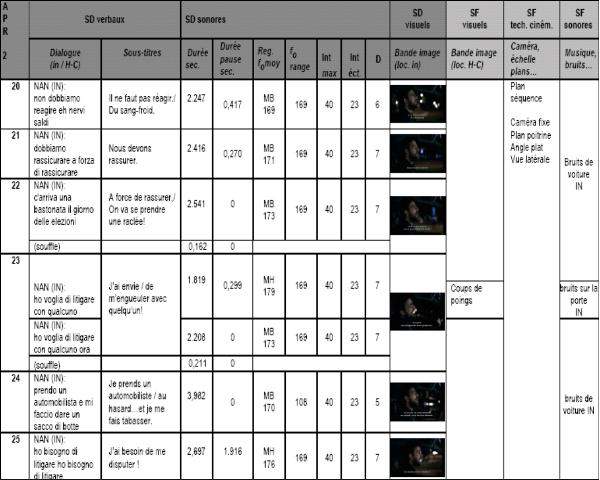
Figure 2 - Romanzo criminale (M. Placido, 2005)
Note
↑ 1 Tout script serait accompagné de variables permettant d’analyser les modalités d’action, le rôle des protagonistes et encore les résultats escomptés. Plus précisément il est normalement décomposé en chapitres, parmi lesquels une suite de « scènes » qui découpent la chaîne des actions et peuvent être adaptées aux situations particulières (Cf. Rossi 2005).
↑ 2 Nous avons ici choisi une transcription des dialogues en orthographe standard, avec ponctuation, pour des raisons de lisibilité. Dans les sous-titres (§ 2.1), le signe « / » indique le passage à la ligne. Nous précisons néanmoins que les conventions de transcription adoptées dans notre modèle descriptif (§1.3) sont différentes ; à ce sujet voir Franzelli 2008a et c.
↑ 3 Vanoye cité par REMAEL 2003: 227.
↑ 4 Pour de plus amples précisions concernant la description des différents signes nous renvoyons à FRANZELLI 2008a et c.
↑ 5 Nous signalons brièvement que pour garantir une certaine lisibilité et intelligibilité, généralement les sous-titres ne peuvent pas dépasser les cinquante frappes, distribuées sur deux lignes, ni un temps d’affichage supérieur aux six secondes ; en outre, le texte ne devrait pas rester à l’écran lorsqu’il y a un changement de plan.
↑ 6 Nous reproduisons ici graphiquement la prononciation du personnage («subbito ») qui est marquée par le redoublement non standard des consonnes typique du parler de Rome.